
自3月份以来,英方先后在西安、济南、深圳、武汉、合肥等多个城市开展了线下的渠道公开课活动,为用户和合作伙伴奉献了多长视听盛宴。为了更好的服务我们的用户和伙伴,经过精心策划的线上“英方技术分享季”也正是开始了,这标志着英方的线上、线下的技术分享实现有有效的结合,在服务形式上也是一次良好的尝试。
4月28日晚20:00点,英方技术分享季第一期正式开始,英方股份华南区技术总监向征伟为带来了《多维度解析英方产品及方案》。今天,就让我们一同回顾一下此次分享的精彩内容:
英方股份成立于09年,是一家专注于容灾及业务连续性解决方案的厂商,英方通过独有的字节级数据捕获与复制技术和数据序列化传输技术(Data Order Transfer,简称DOT)技术为各类企业提供物理及虚拟化或云平台的关键数据和应用的持续保护和快速恢复。最大限度的将因各种存在的物理故障或者逻辑错误导致的宕机及数据丢失损失降到最低。
这些是在此之前我们服务的客户及合作伙伴,篇幅有限,排名不分先后。
我们一起先来看看,传统的IT保护架构,大家看到下面这张图一定非常熟悉,几乎之前我们接触的所有的灾备厂商,都会提供这种解决方案。
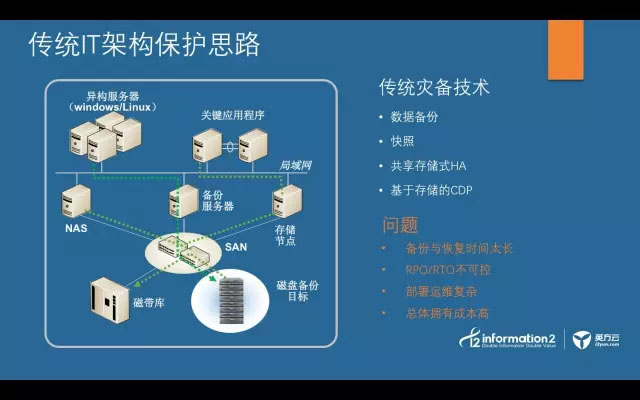
传统的数据及应用保护技术包括数据备份、快照、共享存储式的HA、基于存储的CDP等。在这种架构下的保护方式所面临的问题也是非常明显,数据量越大备份越慢,RTO/RPO不可控,受资源局限性大,对生产主机性能影响大等。用户需求越高,矛盾越突出,那么有没有一种保护架构能在满足用户业务高标准需求的情况下,还能做到游刃有余?答案是显而易见的。
我们知道,用户的基础架构目前正发生着剧烈的变革,我们可以分为四个发展的时代:1.0时代,用户场景中普遍存在的单机架构,从数据及应用的保护来说,是存在数据易丢失,应用易中断的问题的。同时用户基于自身资源的共享考虑,发展出我们的2.0基础架构。即共享存储的管理架构,这个时候,存储资源可以共享,但计算资源仍然分立,从应用连续性上来看,这个架构下,用户希望通过共享存储结合HA软件来实现应用的连续性,但从存储资源的维度来看,若存储物理或者逻辑故障均会导致数据丢失进而引起应用服务中断。这个时候服务器虚拟化技术出现了,一部分用户选择了虚拟化软件提供的相应容灾功能。此时,基础架构演进进入3.0的时代。数据量进一步增加,存储越来越热,相应的用户对于存储的保护需求越来越明显。也就是大家所能认识到的现在越来越多的存储保护解决方案。
在这个基础上用户选择的方式有很多,例如建立双机双柜、引入CDP网关、引入存储容灾网关等多种解决方案来解决存储的单点故障问题。
这个时候,大家都在思考如何解决存储的热点及单点问题,继续之前的存储架构,已经无法适应未来的业务需要,大家迫切的需要解决存储的架构问题。所以分布式存储架构应运而生。
讲到这里,大家已经意识到了,数据保护架构的发展,跟基础架构的发展是不可分的,在不同的发展阶段,用户选择对应阶段的数据保护解决方案。那么分布式存储架构下数据保护架构该如何演进?还能用上之前的基于存储的保护架构吗?
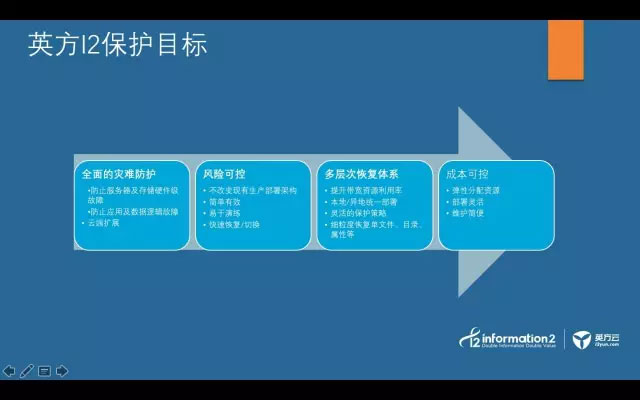
正是云计算的迅猛发展,英方提出了自己的保护目标:即在全生态的灾难防护,新的保护架构除了满足原有物理和逻辑故障的保护外,还能向云端扩展,满足分布式架构的保护需求。
同时要保障风险可控,能适应各种用户的需求场景,灵活部署。并且能提供灾难演练及快速恢复的方法,足够简单有效,不能关键时刻掉链子。所提供的方案要具备多层次的恢复体系,满足本地/异地统一部署,并具有灵活的保护策略和恢复粒度。
以上要求均满足,并不意味着用户需要投入大量的资源和资金,要提供成本可控的解决方案,对于资源的需求足够灵活,并且最重要的是维护足够简便。
那么英方提出以上这些可以说是严苛的目标,是通过什么方式来实现的呢?
首先,我们一起来看看,英方软件提出的保护架构。
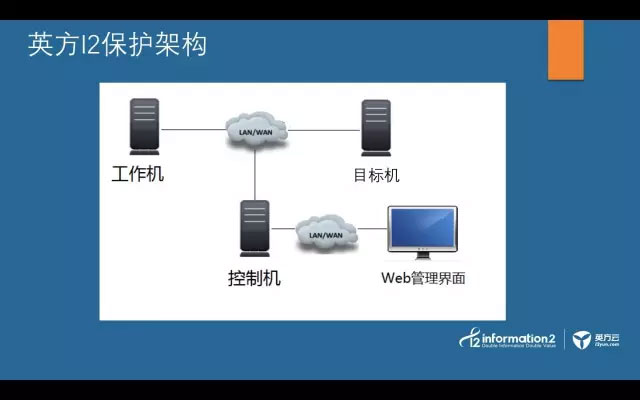
架构很容易理解,我们只需要知道受保护的生产机及数据源端,保护到哪里去(目标端也即灾备机)就好,再加上我们的控制台,就构成了整个应用的保护架构。
从架构上看,英方提出的保护架构是比较直观的,那么英方所提出的字节级序列化复制技术、字节级CDP究竟如何理解呢?
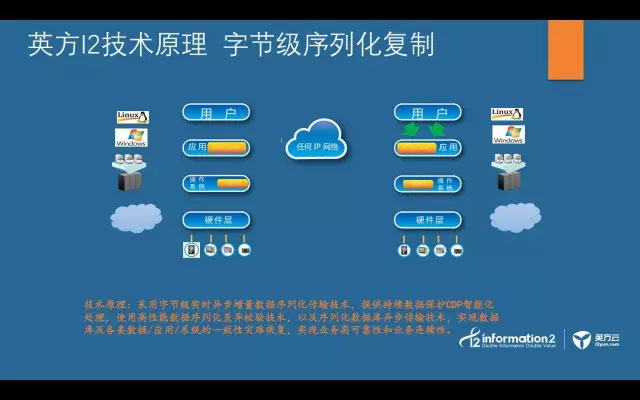
我们知道所有的灾备厂家都在做同一件事情,就是数据的复制技术。从技术的角度来解析,我们可以将复制技术归为四大类:第一层是基于应用的复制技术,与应用强相关;第二类是基于主机的复制技术,这个类别可以分为两个小的类别来看,一类是结合主机及应用复制的备份技术,一类是英方的字节级序列化复制;第三类是基于硬件,也就是基于存储的同步及异步复制,对存储平台有要求。第四类是基于存储协议的路由分发,也就是存储网关的同步及异步复制。
随着复制越往存储层走,数据复制的粒度越粗,例如假设一个条带是64K,那么一个IO就是一个条带的情况下,至少要写64k。同时,对资源的要求会越来越高,例如存储的同步技术对带宽及时延均有要求。并且,复制越往硬件走,一致性问题会越突出。对应到用户的实际感知,要保障一致性,就必须用同步写的机制。
那么英方是如何解决资源及一致性问题的呢?
英方软件的字节级序列化复制,跟所有的复制技术一致,首先需要做初始化的数据镜像,然后,英方的核心复制引擎,开始旁路监听所有文件系统的写操作,例如rename、setattr等,都能准确的捕获,并经过序列化操作后,异步传输到灾备端。完成整个数据的捕获和复制过程。
大家应当发现了,英方的核心引擎工作的时候,并没有复杂的数学运算,也就是,我们对于用户的生产机计算资源占用可以忽略,我们只是旁路捕获数据而已。
另外,我们所有数据都是从内存中捕获,并不涉及生产主机存储的读取操作,也就是说,我们的数据复制过程不占用用户的主机存储IO资源。
因为我们捕获的数据量是以字节为单位,例如我们修改一个300M的文件内容,其中512个字节,我们只需传输这个修改的512字节,对于带宽资源的要求也是极低的。这也是英方软件能实现窄带情况下,异地数据的实时复制的核心技术原理。
说到这里大家可能会问了,那么序列化,在复制过程中起到什么作用?
序列化作为字节级复制技术的一致性保障存在,及所有的数据写的动作在被捕获的时候,我们就会给他打上时间戳,灾备机严格按照时间顺序将收到的数据写在备机存储中。大家知道,网络传输不稳定,我们可能会出现某一个前序时间戳还没收到,收到后续时间戳的场景,那么在这种场景下,我们是一定会等前序时间戳到了后才会写后序时间戳的数据。就这样,通过序列化的技术来保障整个数据复制的一致性,从而保障,不管什么链路情况下,异地存储写下来的数据一定是与主机端的写顺序是一致的。
问答交流环节Q&A:
1、当主备机之间链路出现问题,主备机之间的数据差异是否会导致备机数据库起不来?
答:首先,可以肯定的告诉大家,通过英方软件的字节级序列化复制,数据库一定能起来,我们知道数据库起来的时候,一定会做check DB 的动作,当数据库发现DB和日志不一致时,会执行前滚和回滚的动作。一致性的保障是有序列化这个操作保障的,数据库的前滚和回滚,只是应用层的错误处理流程。用例子来说明,基于存储的复制,要保障一致性,一定是同步IO,因为数据写到存储后,如果用异步,存储再去复制,就不知道那个块先写,哪个块后写当备用存储要被使用时,极有可能某个数据块还没来得急更新,这就是数据不一致了,对应到我们的处理过程,在面对网络故障,有缓存保护,链路恢复,继续传输。主机故障,我有IO还没收到,相当于主机提前关机,再开机一样。
2、问:英方的i2move的原理是怎么样的?如何做到在线p2v的?还有字节放序列化在遇到网络中断很长时间后,被中断的序列化数据包是如何存储和重传的?
答:i2move在做系统的在线迁移时,有个限制性条件,就是主备机的操作系统大版本至少一致,当主备机之间的网络中断时间太长,直到我们设定的内存及硬盘缓冲区都被刷爆了,这个时候,我们会清空缓冲区,等待链路恢复后,进入重镜像的过程,也就是寻找主备机之间的数据差异,达到两边数据一致后,进入下一个循环。
3、问:我使用的服务器厂商已经倒闭了。。还能迁移么?
答:在线迁移与硬件无关,理论上在我们支持列表的操作系统都可以迁移,最典型的,不用硬件厂商倒闭,他从物理机切换到某公有云都是直接支持。
补充问题:仅是工作机出现的情况么?
答:对缓冲只在工作机,有一种情况,备机也需要,就是在我们的两地三中心架构下,备机成为下一个复制节点的主机时,就同样会有缓存区,A->B->C,这个时候B 既是A的备机,又是C的主机。
4、问:请问我们能对外提供公有云云主机的服务吗?
答:我们的i2yun 平台上可以直接购买到阿里、腾讯等合作伙伴的云主机。
5、问:购买云主机后,云灾备是否需要另外购买?
答:需要另外购买
6、问:如有客户要购买云主机,我们英方云的和阿里云,腾讯云相比价格上是一样的吗,还是有差异?
答:作为阿里云、腾讯云的合作伙伴,我们在很多方面上都有优势。
