
为了便于您阅读这篇8000+字的文章,我们将整个文章的架构用一张思维导图勾勒出来。
虽然文末会有关于作者的介绍,但还是想在文章开始就向本文作者刘世民(Sammy Liu)表示感谢。关于HA和DR并不是一个新的概念,但是在云计算的大趋势下,在OpenStack大热的当下,如此完整、实用的关于HA和DR的思考是非常难得且珍贵的,文中列举了大量的具体操作细节,这也是为什么文章标题由原来的“OpenStack高可用和灾备方案”改为“OpenStack高可用(HA)和灾备(DR)解决方案完整操作手册”的原因。另,原文中给出了大量的参考资料链接,但为了阅读的顺畅,链接并未一一列出,您可以“点击此处”继续探索。
基础知识
1.1 高可用 (High Availability,简称 HA)
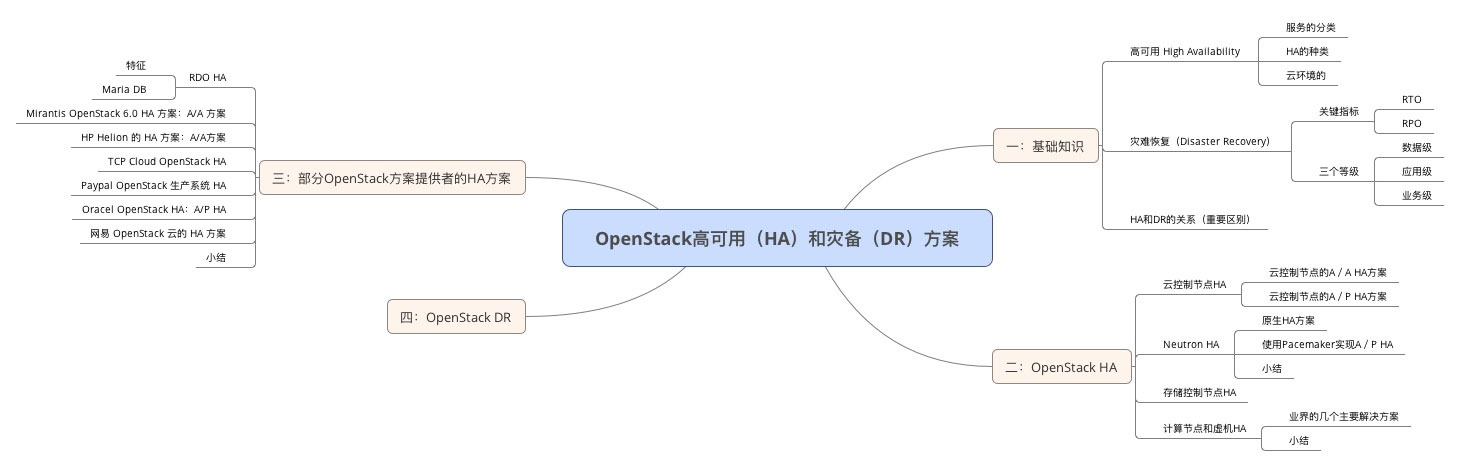
高可用性是指提供在本地系统单个组件故障情况下,能继续访问应用的能力,无论这个故障是业务流程、物理设施、IT软/硬件的故障。最好的可用性, 就是你的一台机器宕机了,但是使用你的服务的用户完全感觉不到。你的机器宕机了,在该机器上运行的服务肯定得做故障切换(failover),切换有两个维度的成本:RTO (Recovery Time Objective)和 RPO(Recovery Point Objective)。RTO 是服务恢复的时间,最佳的情况是 0,这意味着服务立即恢复;最坏是无穷大意味着服务永远恢复不了;RPO 是切换时向前恢复的数据的时间长度,0 意味着使用同步的数据,大于 0 意味着有数据丢失,比如 ” RPO = 1 天“ 意味着恢复时使用一天前的数据,那么一天之内的数据就丢失了。因此,恢复的最佳结果是 RTO = RPO = 0,但是这个太理想,或者要实现的话成本太高,全球估计 Visa 等少数几个公司能实现,或者几乎实现。
对 HA 来说,往往使用共享存储,这样的话,RPO =0 ;同时往往使用 Active/Active (双活集群) HA 模式来使得 RTO 几乎0,如果使用 Active/Passive 模式的 HA 的话,则需要将 RTO 减少到最小限度。HA 的计算公式是[ 1 - (宕机时间)/(宕机时间 + 运行时间)],我们常常用几个 9 表示可用性:
2 个9:99% = 1% * 365 = 3.65 * 24 小时/年 = 87.6 小时/年的宕机时间
4 个9: 99.99% = 0.01% * 365 * 24 * 60 = 52.56 分钟/年
5 个9:99.999% = 0.001% * 365 = 5.265 分钟/年的宕机时间,也就意味着每次停机时间在一到两分钟
11 个 9:几乎就是几年才宕机几分钟。
1.1.1 服务的分类
HA 将服务分为两类:
有状态服务:后续对服务的请求依赖于之前对服务的请求。
无状态服务:对服务的请求之间没有依赖关系,是完全独立的。
1.1.2 HA 的种类
HA 需要使用冗余的服务器组成集群来运行负载,包括应用和服务。这种冗余性也可以将 HA 分为两类:
Active/Passive HA:集群只包括两个节点简称主备。在这种配置下,系统采用主和备用机器来提供服务,系统只在主设备上提供服务。在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型地,可以采用 CRM 软件比如 Pacemaker 来控制主备设备之间的切换,并提供一个虚机 IP 来提供服务。
Active/Active HA:集群只包括两个节点时简称双活,包括多节点时成为多主(Multi-master)。在这种配置下,系统在集群内所有服务器上运行同样的负载。以数据库为例,对一个实例的更新,会被同步到所有实例上。这种配置下往往采用负载均衡软件比如 HAProxy 来提供服务的虚拟 IP。
1.1.3 云环境的 HA
云环境包括一个广泛的系统,包括硬件基础设施、IaaS层、虚机和应用。以 OpenStack 云为例:
云环境的 HA 将包括:应用的 HA、虚机的 HA、云控制服务的 HA、物理IT层(包括网络设备比如交换机和路由器,存储设备等)、基础设施(比如电力、空调和防火设施等)。
本文的重点是讨论 OpenStack 作为 IaaS 的 HA。
1.2 灾难恢复 (Disaster Recovery)
几个概念:
灾难(Disaster):是由于人为或自然的原因,造成一个数据中心内的信息系统运行严重故障或瘫痪,使信息系统支持的业务功能停顿或服务水平不可接受、达到特定的时间的突发性事件,通常导致信息系统需要切换到备用场地运行。
灾难恢复(Diaster Recovery):是指当灾难破坏生产中心时在不同地点的数据中心内恢复数据、应用或者业务的能力。
容灾:是指除了生产站点以外,用户另外建立的冗余站点,当灾难发生,生产站点受到破坏时,冗余站点可以接管用户正常的业务,达到业务不间断的目的。为了达到更高的可用性,许多用户甚至建立多个冗余站点。
衡量容灾系统有两个主要指标:RPO(Recovery Point Objective)和 RTO(Recovery Time Object),其中 RPO代表 了当灾难发生时允许丢失的数据量,而 RTO 则代表了系统恢复的时间。RPO 与 RTO 越小,系统的可用性就越高,当然用户需要的投资也越大。
大体上讲,容灾可以分为3个级别:数据级别、应用级别以及业务级别。
1.3 HA 和 DR 的关系
两者相互关联,互相补充,互有交叉,同时又有显著的区别:
HA 往往指本地的高可用系统,表示在多个服务器运行一个或多种应用的情况下,应确保任意服务器出现任何故障时,其运行的应用不能中断,应用程序和系统应能迅速切换到其它服务器上运行,即本地系统集群和热备份。HA 往往是用共享存储,因此往往不会有数据丢失(RPO = 0),更多的是切换时间长度考虑即 RTO。
DR 是指异地(同城或者异地)的高可用系统,表示在灾害发生时,数据、应用以及业务的恢复能力。异地灾备的数据灾备部分是使用数据复制,根据使用的不同数据复制技术(同步、异步、Strectched Cluster 等),数据往往有损失导致 RPO >0;而异地的应用切换往往需要更长的时间,这样 RT0 >0。 因此,需要结合特定的业务需求,来定制所需要的 RTO 和 RPO,以实现最优的 CTO。
也可以从别的角度上看待两者的区别:
从故障角度,HA 主要处理单组件的故障导致负载在集群内的服务器之间的切换,DR 则是应对大规模的故障导致负载在数据中心之间做切换。
从网络角度,LAN 尺度的任务是 HA 的范畴,WAN 尺度的任务是 DR 的范围。
从云的角度看,HA 是一个云环境内保障业务持续性的机制,DR 是多个云环境间保障业务持续性的机制。
从目标角度,HA 主要是保证业务高可用,DR 是保证数据可靠的基础上的业务可用。
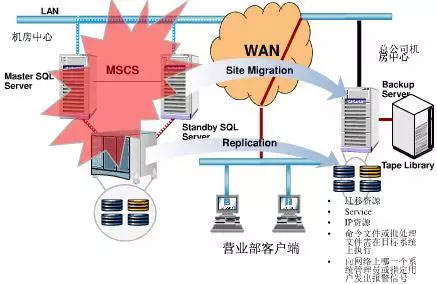
一个异地容灾系统,往往包括本地的 HA 集群和异地的 DR 数据中心。一个示例如下:
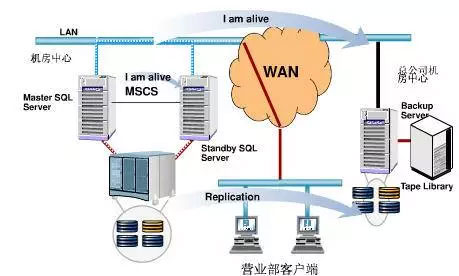
Master SQL Server 发生故障时,切换到 Standby SQL Server,继续提供数据库服务:
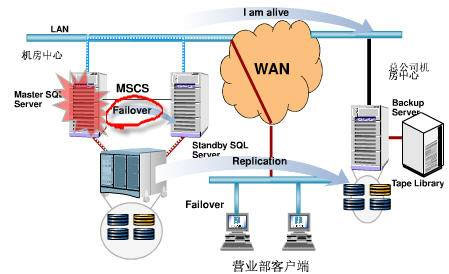
在主机房中心发生灾难时,切换到备份机房(总公司机房中心)上,恢复应用和服务:
OpenStack HA
OpenStack 部署环境中,各节点可以分为几类:
Cloud Controller Node (云控制节点):安装各种 API 服务和内部工作组件(worker process)。同时,往往将共享的 DB 和 MQ 安装在该节点上。
Neutron Controller Node (网络控制节点):安装 Neutron L3 Agent,L2 Agent,LBaas,VPNaas,FWaas,Metadata Agent 等 Neutron 组件。
Storage Controller Node (存储控制节点):安装 Cinder volume 以及 Swift 组件。
Compute node (计算节点):安装 Nova-compute 和 Neutron L2 Agent,在该节点上创建虚机。
要实现 OpenStack HA,一个最基本的要求是这些节点都是冗余的。根据每个节点上部署的软件特点和要求,每个节点可以采用不同的 HA 模式。但是,选择 HA 模式有个基本的原则:
能 A/A 尽量 A/A,不能的话则 A/P (RedHat 认为 A/P HA 是 No HA)
有原生(内在实现的)HA方案尽量选用原生方案,没有的话则使用额外的HA软件比如Pacemaker等
需要考虑负载均衡
方案尽可能简单,不要太复杂
OpenStack官方认为,在满足其HA要求的情况下,可以实现IaaS的99.99%HA,但是,这不包括单个客户机的 HA.....
限于篇幅,更多内容关注微信公众号:i2soft查看,或直接点击“原文”进行阅读。
