部分用户文件误隔离的处理公告
尊敬的客户:因云盾升级触发bug,导致部分服务器的少量文件被系统误隔离。我们已经第一时间启动系统回滚,被误隔离的文件正在陆续恢复,您无需进行手动恢复操作,请耐心等待。针对被影响的客户,我们会提供统一百倍赔偿。对您带来的不便我们深表歉意。
-阿里云计算有限公司 2015年9月1日
“阿里事件的详细过程及不用描述了,如果能承诺100倍的赔偿,就知道事件有多严重,至少携程没有承诺100倍的赔偿。赞赏阿里的勇气和担当,在这个时刻搞云计算的,没有一个人应该感到庆幸,这个事件不光是阿里的事件,也是整个云计算行业的大事件…”
其实云计算领域宕机意外时有发生,不管是AWS,微软Azure都曾经出现过宕机断服的情况。2011年亚马逊北弗吉尼亚的云计算中心宕机,导致了Quora/新闻服务Reddit等等服务收到影响,2012年微软Azure的宕机更是导致全球范围云主机停机,2013,2014,2015宕机是意外事件,,与计算机技术的高速发展形影相随,不是属于过去,也不会绝迹于未来。我们需要的是未雨绸缪、沉着应对老板电话号码。
“互联网行业一直都是针对个人用户2C,到搞云计算的时候,已经形成习惯,强调性价比,强调易用性,强调可视化!于是忘了,最重要的第一是稳定,第二还是稳定,第三还是稳定。云服务的大部分是企业用户,企业用户最关心的是稳定,离开稳定谈任何功能都是耍流氓...”
其实,任何稳定都是相对的,可靠性不仅仅建立在单体云主机的基础之上,更应该从整体系统的角度来考虑,对云计算的安全性的认识不应该停留在:幸灾乐祸,人云亦云。稳定/可靠确实很重要,但意外是正常的小概率事件,作为用户要正视这些灾难性的危机时刻,在任何情况下,不忘记建立自己的一整套业务连续性方案。充分享受云计算经济便捷,同时冷静对待和处理意外情况的出现,保证企业业务连续。
这不仅仅是传统物理主机/云主机厂商的责任,更是用户自身必须认识认知的基本常识。
对于关键业务,我们应该采用业务连续性思维方式,构建企业级业务连续性规划,从技术上说,最基本的就是提前配置高可用云主机解决方案,并且在做关键升级时能够提前规避和考虑各类风险。
云计算作为大规模集约化的复杂的新技术,出现故障,应该保持客观的平常心,操作和放大阿里事件,是哗众取宠,是非常不专业的。藉此看成云计算行业危机,更是因噎废食、杞人忧天。
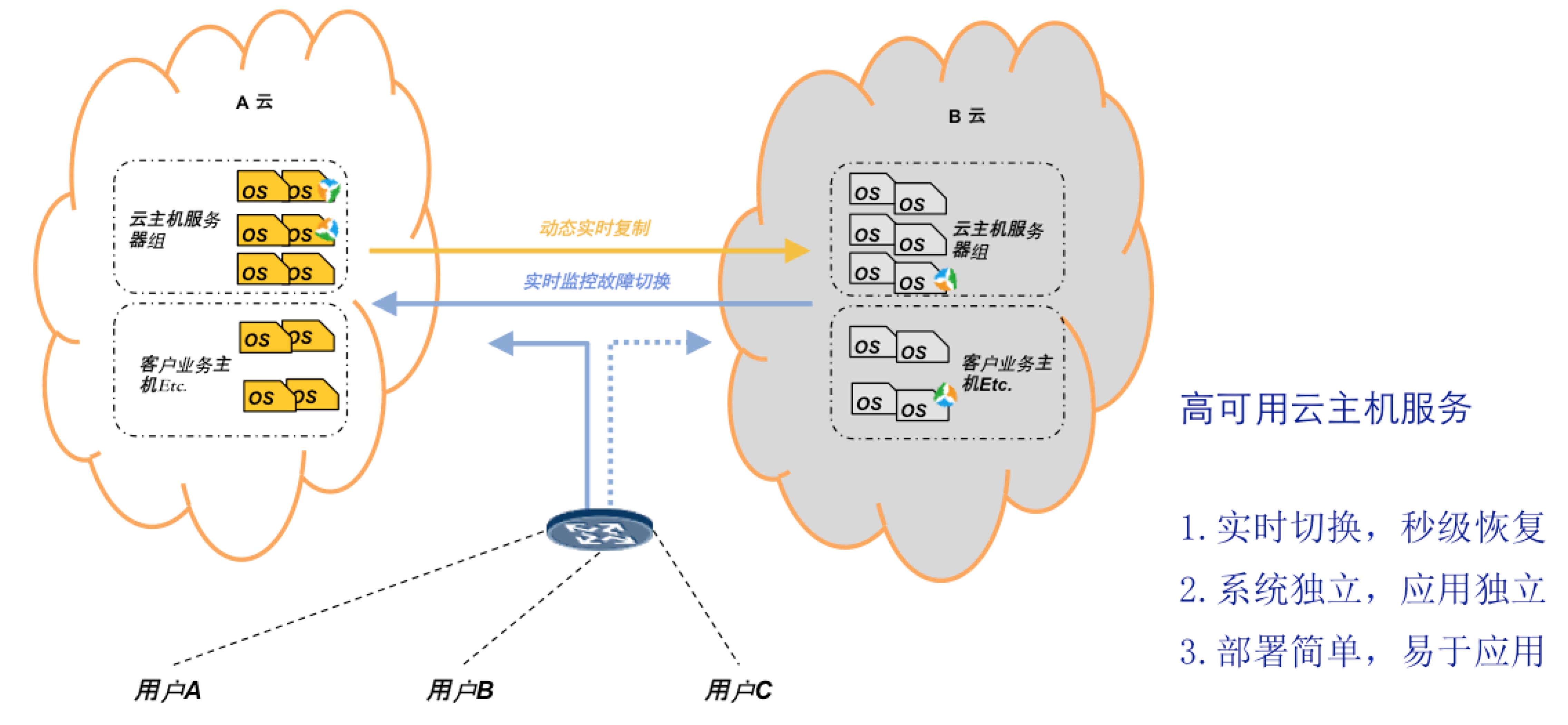
未雨绸缪,尽快建立业务连续性解决方案,云计算可以停机,愿您的业务“永不停机”!

